最近比较流行使用姓名首字母作为头像, 而我们的产品也有类似的需求。有同事写了个头像服务,我看了下目前网上还没有 Go 版的 initials avatar 库, 就想着弄个轮子。 原来的代码可能是写的仓促, 看起来并不是很清晰, 于是我剥离了原来的业务需求,写了个简单的库。本以为自己写的还可以, 结构看起来很清晰, 谁知道,压力测试过程中, 各种panic, 惨不忍睹!
1
2
3
4
5
6
7
8
9
10
11
12
|
$ wrk -t12 -c400 -d30s http://10.20.142.147:3000/avatar/bdsad
Running 30s test @ http://10.20.142.147:3000/avatar/bdsad
12 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 337.86ms 349.12ms 1.77s 88.22%
Req/Sec 73.50 36.62 200.00 66.54%
26954 requests in 30.03s, 57.89MB read
Socket errors: connect 0, read 407, write 0, timeout 1860
Non-2xx or 3xx responses: 488
Requests/sec: 897.54
Transfer/sec: 1.93MB
|
从上面的数据看来,性能极其低下。 本着好奇心, 我也对同事的代码压测了。 结果数据(见下面)表明,人家的性能就是棒棒哒!居然是我的性能的13倍!
1
2
3
4
5
6
7
8
9
10
| $ wrk -t12 -c400 -d30s http://10.20.142.147:11250/avatar/a
Running 30s test @ http://10.20.142.147:11250/avatar/a
12 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 33.28ms 35.89ms 338.68ms 86.76%
Req/Sec 1.01k 178.65 1.59k 73.75%
360226 requests in 30.00s, 625.58MB read
Socket errors: connect 0, read 206, write 0, timeout 0
Requests/sec: 12007.53
Transfer/sec: 20.85MB
|
这种情况下,肯定得对代码进行调优。Go 提供了pprof工具可用于性能分析。我选用了 Dave Cheney 提供的更友好的 profile工具。关于profile 的使用, 之前有人写过一篇教程, 我同事也写过一篇对其项目 kingshard 进行调优的文章,里面也介绍了profile 的使用, 这里不再赘述。
看了下代码, 发现有两处写搓了。 其一 是每次来请求都要 new 一个对象,这种做法是不科学的,当时我一定是脑残了。其二 是每次都会对 image.Image 进行 Encode, 这本来就是个耗时的操作, 也是脑残了。
当时的优化策略是选用 LRU 作为缓存。 再次压测, 发现虽然慢了点, 但也不至于会panic 造成服务不可用了。性能也稍微提升了点。但是,难道 LRU的作用就这么有限? 再次 profiling, 发现还是对 image.Image 进行encode时耗时过多, 而且还有内存泄漏的嫌疑(见下图)

1
2
3
4
5
6
7
8
9
10
11
12
|
$ wrk -t12 -c400 -d30s http://10.20.142.147:3000/avatar/a
Running 30s test @ http://10.20.142.147:3000/avatar/a
12 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 212.30ms 278.73ms 2.67s 86.38%
Req/Sec 120.37 54.38 249.00 60.72%
36199 requests in 30.07s, 63.83MB read
Socket errors: connect 0, read 187, write 1, timeout 1953
Non-2xx or 3xx responses: 1
Requests/sec: 1204.01
Transfer/sec: 2.12MB
|
这次 我准备改写逻辑, 不再返回 image.Image, 而是返回转换后的 []byte, 虽然转换过程也会耗时, 但是我把 LRU 逻辑从 draw.go 移出到 avatar.go。至少有 LRU顶着, 不至于性能很差。
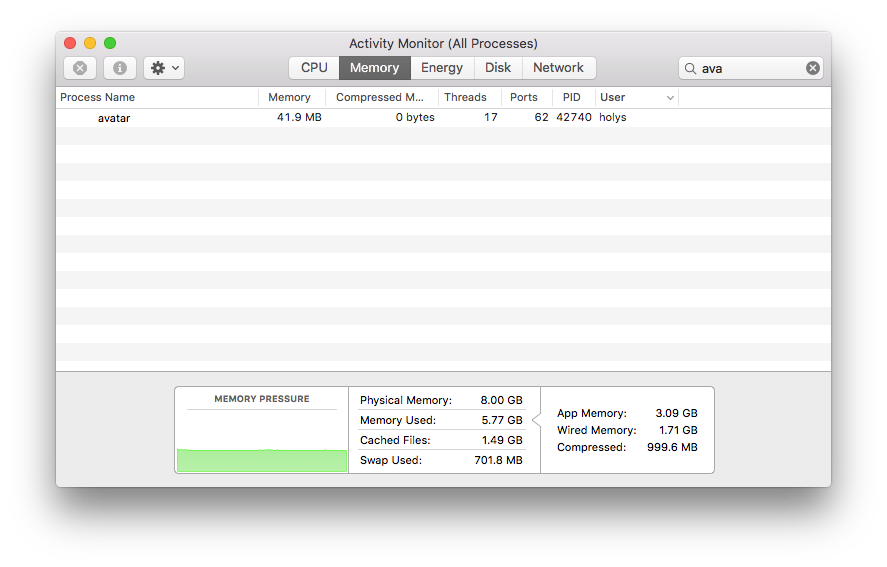
改好后,再跑一次, 效率惊人。 本来本地跑的服务, 一般是毫秒级别,现在已经到了微秒级别,而且内存占用也还理想(见下图)。性能已经是我同事写的那个的两倍了!
1
2
3
4
5
6
7
8
9
10
11
12
|
$ wrk -t12 -c400 -d30s http://10.20.142.147:3000/avatar/a
Running 30s test @ http://10.20.142.147:3000/avatar/a
12 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 13.97ms 19.39ms 146.91ms 95.05%
Req/Sec 1.94k 0.96k 4.74k 67.19%
686848 requests in 30.01s, 1.18GB read
Socket errors: connect 0, read 200, write 24, timeout 1873
Non-2xx or 3xx responses: 1
Requests/sec: 22889.01
Transfer/sec: 40.36MB
|
以上的情况都是开了logger的, 如果关掉logger, 性能更猛,又飙升了一倍,可见写日志是多么的影响性能。
1
2
3
4
5
6
7
8
9
10
11
12
|
$ wrk -t12 -c400 -d30s http://10.20.142.147:3000/avatar/a
Running 30s test @ http://10.20.142.147:3000/avatar/a
12 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 7.53ms 11.28ms 195.48ms 96.19%
Req/Sec 3.66k 2.29k 47.47k 75.96%
1285314 requests in 30.00s, 589.60MB read
Socket errors: connect 0, read 276, write 0, timeout 1872
Non-2xx or 3xx responses: 1
Requests/sec: 42849.74
Transfer/sec: 19.66MB
|
最后, 卖个广告:initials-avatar
总结:
- 写代码要严谨;
- 性能出问题不要怕,一步步调优。
本文地址 http://holys.im/2015/11/13/profiling/