背景:
service_event 服务,是下文提到的消费者服务,会消费 rabbitmq 里面的消息。
每个服务起 10 个消费者线程去消费消息,如果连接断开,隔 1秒后会重连。service_event用到的线上环境的rabbitmq 一览:
(A机房的 rabbitmq 是两两节点一个集群,下面的排序不是按集群来,这对本文来说不重要,重要的是“版本号是统一的”)
1 | A-rabbitmq04.bj: {rabbit,"RabbitMQ","3.5.3"}, |
(这是 B 机房中出现问题的集群,当事人之一,在本案中的现象为:消费者都跑掉了,最终为一个消费者都没有)
1 | B-rabbitmq01.bj: {rabbit,"RabbitMQ","3.5.3"}, |
(这是 B 机房中的另一个集群,在本案中现象为: 消费者都跑这边来了)
1 | B-rabbitmq04.bj: {rabbit,"RabbitMQ","3.6.0"}, |
可以看到,A 机房的版本是统一的,为 3.5.3, B 机房的版本,其中一个集群是 3.5.3, 另一个是 3.6.0
LVS: 这也是当事人之一,差点成了窦娥。事实证明它是无辜的(当然还得后面的改进方案实施后,观察没问题才能彻底洗白). RabbitMQ 集群并不直接暴露给客户端,而是通过 LVS 作为前端,顺带负载均衡。
LVS 使用了 WRR 负载均衡算法。
关于rabbitmq 的心跳:
如果是客户端设定的值小于 1秒, 则以服务端的为准。
测试环境是 RabbitMQ 3.1.1, 默认心跳值为 600秒
实测也是 600秒(wireshark 抓包):

一开始观察到的现象
B 机房的 01/02/03 这个集群的 EventOrder 队列出现消息没有被消费。 正常是: 消息数量会不断变化,而不是停留在某个值上。
并不是一开始就没有消费,而是过一段时间才出现这种情况。 而重启消费者服务后,堆积的消息马上被消费掉。
一开始大伙儿都认为是 LVS 有问题。
其实这里有疑点:
A, B 机房的 LVS 是一样的,为什么就其中一个出了问题,说不过去呀。
第一次分析过程
业务访问的是 rabbitmq01.sys.srv, 这只是个 LVS 域名。
如果是来自 A 机房的访问,LVS 会解析域名到 A 的 rabbitmq 集群。
如果是来自 B 机房的访问, LVS 会解析域名到 B 的 rabbitmq 集群。
集群分布:
A 机房目前提供了7个 rabbitmq 集群, 其中每个集群都是两个节点,其中一个节点为内存节点,另一个节点为磁盘节点(数据落地)
B 机房目前提供了 2个 rabbitmq 集群, 其中一个集群是 三个节点(编号1、2、3,1 是内存节点,2 、 3 是磁盘节点), 另一个集群是 两个节点(编号4、5,其中4为磁盘节点,5 为内存节点)
集群之间的数据是不共享的。一般而言,数据也不跨机房传输,除非是出现一个机房全部宕机(?)
已知: 无论是生产者还是消费者都是使用长连接。
并不是一开始就没有消费,而是过一段时间才出现这种情况, 可能是 idle 时间过长, 连接被 LVS drop掉(正常),然后重连的时候,就没有连上 目标集群,导致目标集群的消息一直没有被消费掉。
B 机房部署了 4个 消费服务,每个消费服务里面有10个线程去消费,每个线程使用一个长连接。
而 B 机房一共两个集群,难道 40 个连接都没法命中堆积消息的那个集群的任何一个节点?
质疑1: LVS 有问题?如何定位问题?
质疑2: 真的是重连有问题? 如果是重连有问题,那重启服务也算重连吧,怎么就没问题了呢?
work around
既然是连接断掉之后才引起的问题,那如何避免连接长时间不活跃?
内核默认的 keepalive time 是 7200秒, 远大于目前 lvs 360 秒的设定,也就是没啥卵用,远水救不了近火。
可以改 keepalive time, 但是这个改动会影响当前主机上的所有使用 TCP 的服务,
还有一种办法是 rabbitmq 自带的 heartbeat 功能, 这个只会影响 rabbitmq 本身。
但是 无论是 heartbeat 还是 keepalive, 都具有两个特点:保活好的连接,剔除坏的连接。
如果一个连接只是空闲,但是没有断,保活是可以的,一旦断了(即使是短期可恢复的),被心跳包发现后,
也就永远断了。感觉现在最大的问题不是连接为什么断(超时就断很正常),而是重连后某个集群的消费者不见了。
heartbeat 虽然不治本,但是能治标吗?
上面只是我的个人猜测,然后我去找同事 @zhangqin 聊了下,发现一个重大线索:
出现消息堆积的时候, 目标集群的目标队列一个消费者都没有。他自己改了心跳值后(改为5秒),就没出现这种问题,而且 另一个项目 freeman 也是这么干的,也没出现过这种问题。
看样子, 心跳好像能解决问题,但还是有些疑点没有得到解答: 如 为何线上看到的 60s 心跳不能解决问题,而 5秒就能解决问题?但都是小于 LVS 的 360 秒呀!
于是开始做实验来验证:
实验过程
实验1
用默认心跳(就是什么都没改)。 观察 B 机房的 rabbitmq 集群情况(分别是 01/02/03 和 04/05 )。
每隔 6分钟(刚好和 lvs 的 timeout 值吻合),断掉一大批空闲连接 N 个,然后重连 N 个,但是每一次重连,都是连 04/05 集群居多,久而久之(每隔六分钟一次), 01/02/03 这个集群的消费者越来越少,最终应该是 一个消费者都没有了。
注意: 重连后的 消费者总数是不变的,因为重连都是成功的,只是一边倒了。
从下图来看,非常直观的看出来 每隔六分钟 重连一大批(LVS: 怪我咯)
(注意:下图来自Kibana 日志截图,高度不代表消费者数量。日志记录了重连活动,所以只是反映重连的时间)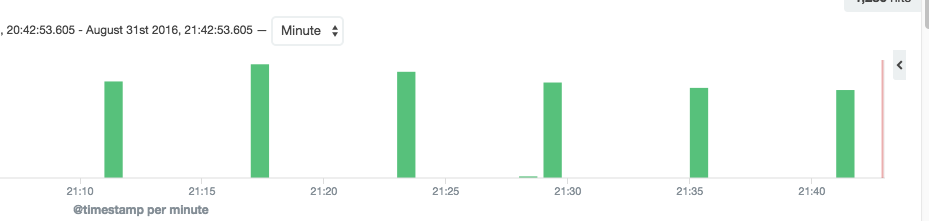
这个集群的目标队列 只剩下一个消费者了 (最开始的时候是 16个)

绝大多数消费者都跑到 另一个集群了最终有39个(最开始的时候是24个)
备注: B 机房共有4个服务实例,每个实例是10个消费者,刚好 16 + 24 = 4 * 10 = 40
实验2
心跳改为10秒,看是否对连接数有影响。
启动时间为 22:05
01/02/03 集群: 23个
04/05 集群: 17个
第二次观察时间: 第二天早上 09:01
01/02/03: 23 个
04/05:17个
看样子心跳值为 10秒时起作用。
问: 为什么 60 s 的默认心跳值没起作用?
实验3
使用 rabbitmq server 默认心跳
虽然 实验1 也是用了默认心跳,但是当时忘了观察实际的心跳值,所以重做。
发现重大线索: 特么的版本不一致! 而且两个版本对应的默认心跳时间也不一样。基本上所有疑点都得到解答了。
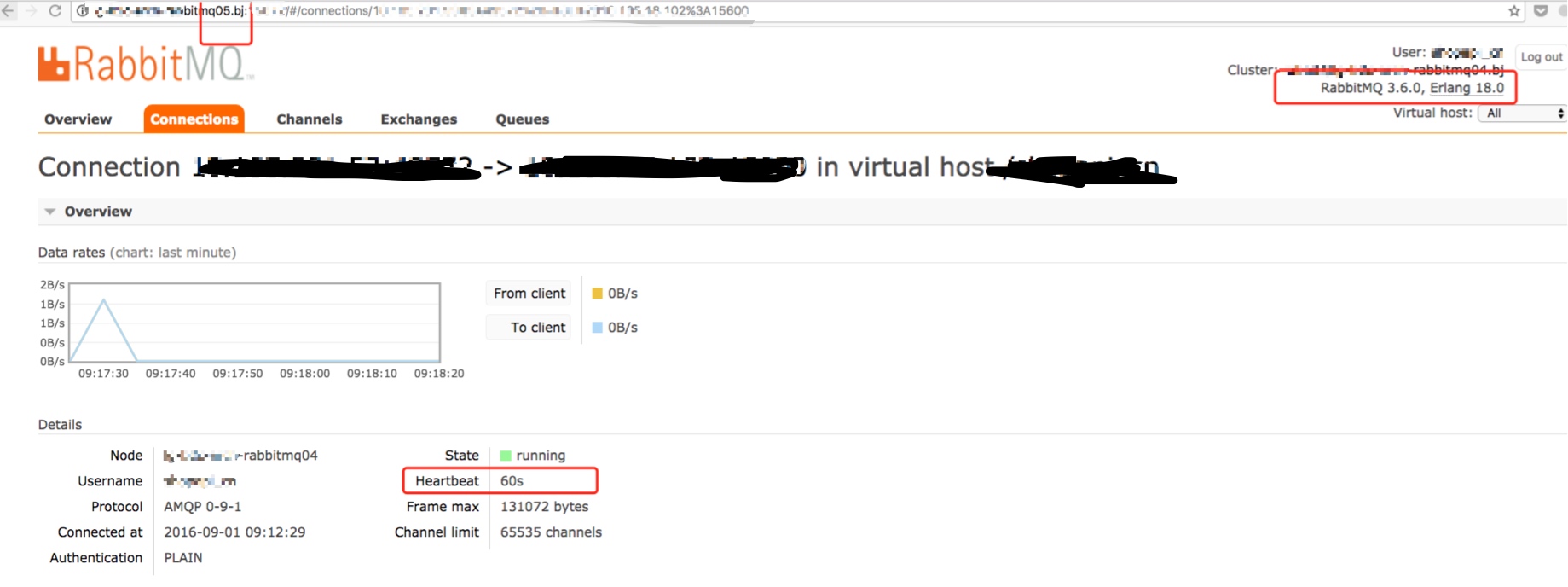
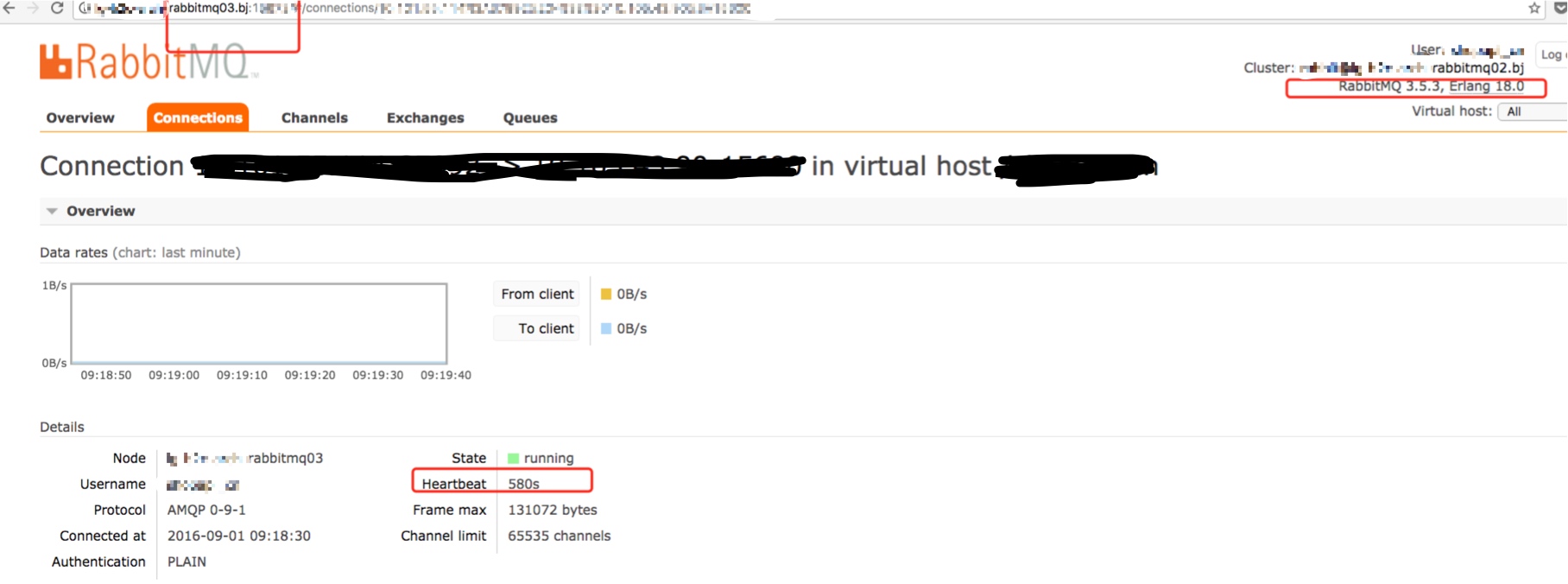
原因分析
(看官此时可翻到最上面看背景介绍)
A 机房集群之所以没出问题,是因为 A 机房的 rabbitmq 都是统一版本,即 3.5.3, 其默认心跳都是580 s, 由于服务端和客户端都没有配置心跳,所以都是用了580s 这个值,远大于 lvs 设置的 360 s timeout, 也就是 lvs 必杀之。但是因为死的很均匀,重连后也是很均匀,所以没出问题(每个集群都有消费者)
B 机房集群之所以出问题, 是因为 B 机房的 rabbitmq 存在两个版本。
一个是 3.5.3, 默认心跳是 580 秒,远大于 lvs 的 360 秒, 也就是 lvs 必杀之。
一个是 3.6.0, 默认心跳是 60 秒,远小于 lvs 的 360 秒,空闲连接不会被 drop, 因为有心跳。
问题来了: 04/05 集群(版本3.6.0)的连接一直保持着,没断过(即使空闲,因为有心跳), 01/02/03集群(版本3.5.3) 每隔 360 秒必断(当然是空闲时,因为没有心跳), 然后重连时 LVS 使用 WRR 负载均衡算法,虽然能保证两边都有连接,但是久而久之,3.5.3 版本的集群肯定是越来越少连接,直至 0, 造成消息堆积现象。
来个稍微直观的图表:
假设一开始两个集群的消费者是均等的,每次重连后,分配就开始失衡。直到最后完全偏向一边。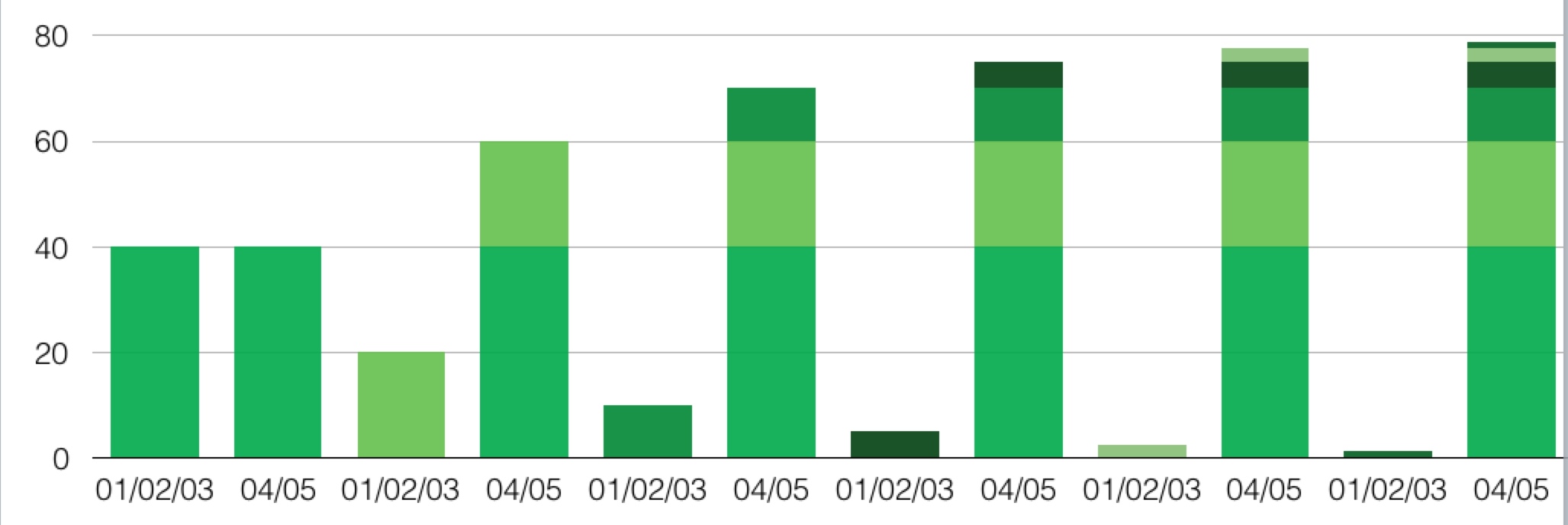
解决办法
根本原因:不一致的心跳值。
有很多办法可以解决:
- 统一 rabbitmq server 版本,需要升级,风险略大;
- 统一服务端的心跳值,心跳值必须小于 LVS 的默认 timeout;
- 统一客户端的心跳值,心跳值必须小于 LVS 的默认 timeout。
总结
一开始让我去分析这个问题,我内心是拒绝的,因为我一不懂 rabbitmq(只听过,没深入了解过),二不懂 LVS(只听过,没深入了解过)。总之一开始是一头雾水,不知从哪里开始。连对现象的准确描述也做不到。而且也不好重现与模拟(线上)。 不过第一感觉,这应该跟TCP连接有关,Google 过 rabbitmq connection timeout 相关问题,找到关于 heartbeat 相关资料,但是不确定是不是这个问题。
多方请教。 请教过多位同事。 每一次请教,使线索越来越清晰。尤其是当 @zhangqin 告诉我,他自己改了心跳值后,就没出现这种问题,而且 freeman项目也是这么干的,也没出现过这种问题。虽然看起来 it works, 但是还是有很多疑点没有得到解答。不过此时应该算接近答案的 80% 了,剩下的只需按图索骥,多次做实验对比结果。
豁然开朗: 就当我准备进行第三次实验,看看用默认心跳会怎样,突然发现待实验的两个集群 其版本不一样, 而且默认心跳值也不一样。之前内心问了一万个为什么的“为什么都是 60s 心跳值却还是会断开连接?” 疑惑终于得到解答,有种拨云见日的感觉。特么版本是不一样的啊!!! 至此, 几乎所有疑问都得到解答,然后再请运维同学查询下所有的rabbitmq 版本,发现 A 机房的版本是统一的,所以它不会出问题(统一的话,要么全断,要全不断,不会出现一部分断,一部分不断)
对于工作中要用到的东西要深入了解,有时候答案就在那里,你知道的越多,找答案就越快。
这篇文章改过好几次,感觉写起来思路依然不是那么的清晰,毕竟当时思路就不是清晰的!!!都是一步步(有错的尝试,也有对的尝试)试探出来的。
参考文档
本文地址 http://holys.im/2016/09/20/why-rabbitmq-message-not-consumed/